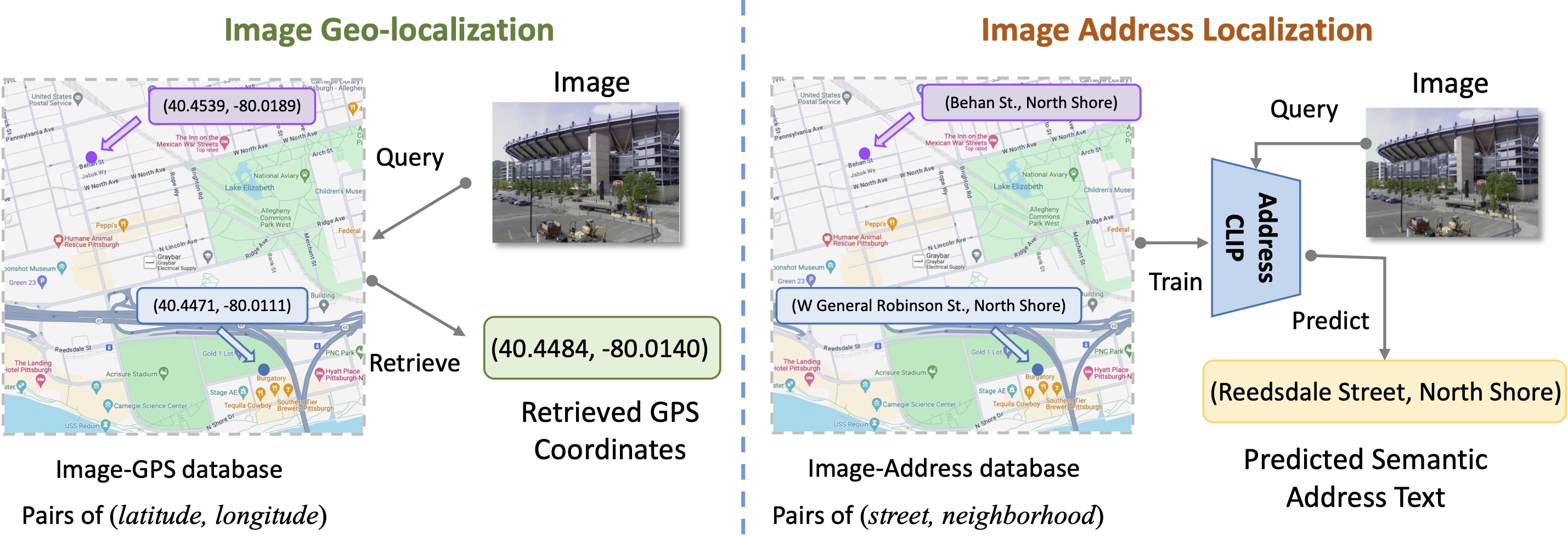
In this study, we introduce a new problem raised by social media and photojournalism, named Image Address Localization (IAL), which aims to predict the readable textual address where an image was taken. Existing two-stage approaches involve predicting geographical coordinates and converting them into human-readable addresses, which can lead to ambiguity and be resource-intensive. In contrast, we propose an end-to-end framework named AddressCLIP to solve the problem with more semantics, consisting of two key ingredients: i) image-text alignment to align images with addresses and scene captions by contrastive learning, and ii) image-geography matching to constrain image features with the spatial distance in terms of manifold learning. Additionally, we have built three datasets from Pittsburgh and San Francisco on different scales specifically for the IAL problem. Experiments demonstrate that our approach achieves compelling performance on the proposed datasets and outperforms representative transfer learning methods for vision-language models. Furthermore, extensive ablations and visualizations exhibit the effectiveness of the proposed method.
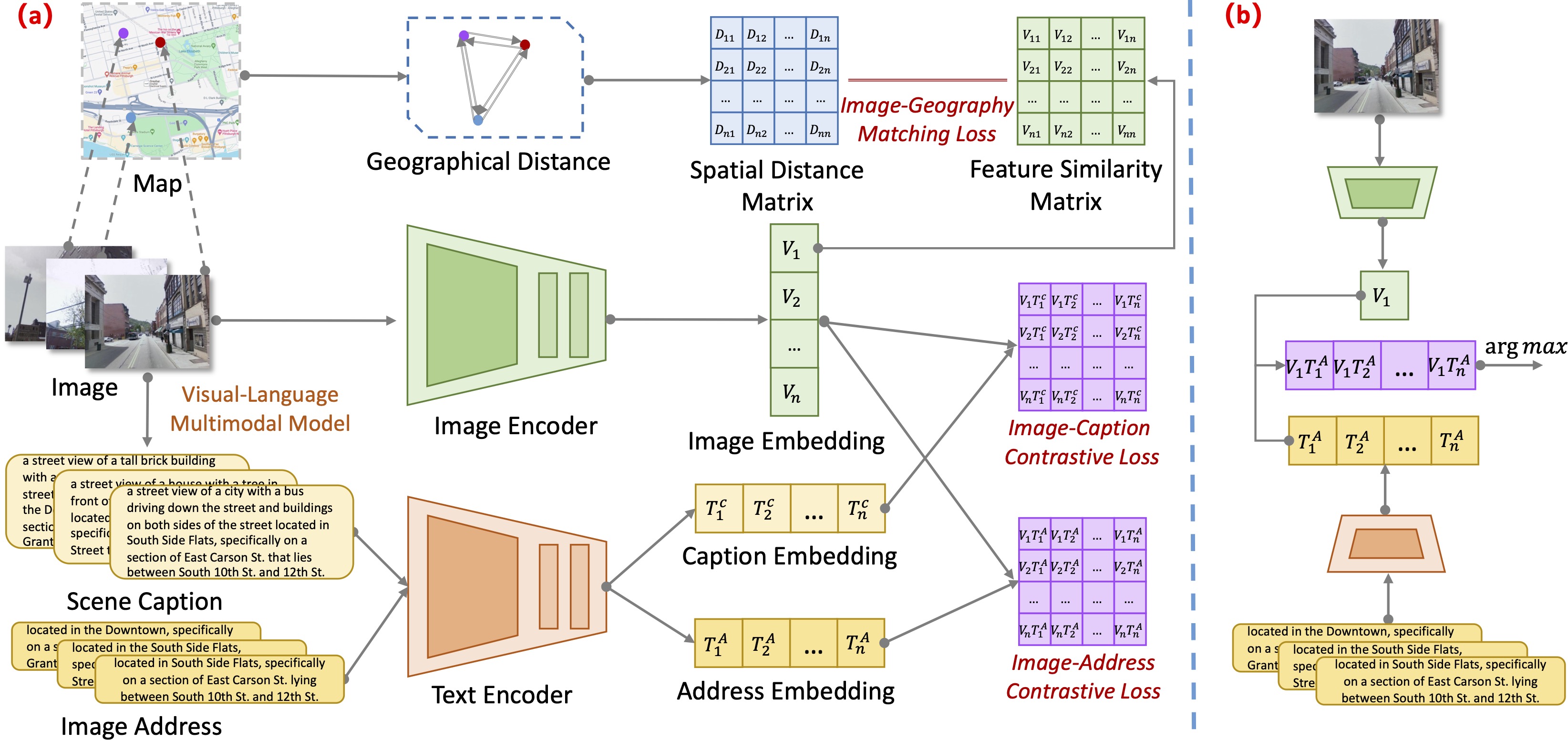
We formulate the IAL problem as a vision-text alignment problem between the image and address pairs. The above figure depicts the framework of our method. During training, the embeddings of the image and the address are extracted by the image encoder and text encoder, respectively, and are then aligned through image-address contrastive learning. An additive scene caption is introduced as a supplement to the address to enrich the plain text information. The scene caption shares the same text encoder with the image address, and the resulting caption embedding and image embedding are combined for image-caption contrastive learning. Furthermore, we adopt the geographical position information as a guide to increase the similarities between geographically close image features while increasing the differences between geographically distant image features. The image-geography matching is learned between geospatial distance and image feature similarity. During inference, the address with the highest similarity to the query image’s embedding indicates the most probable address.
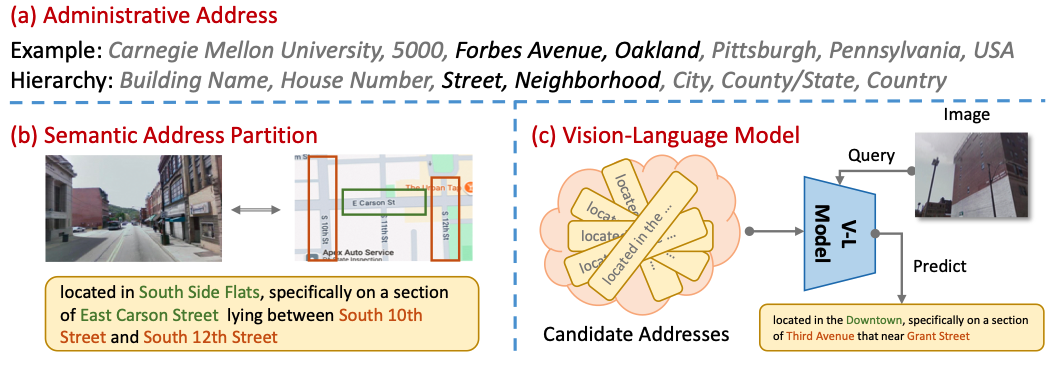
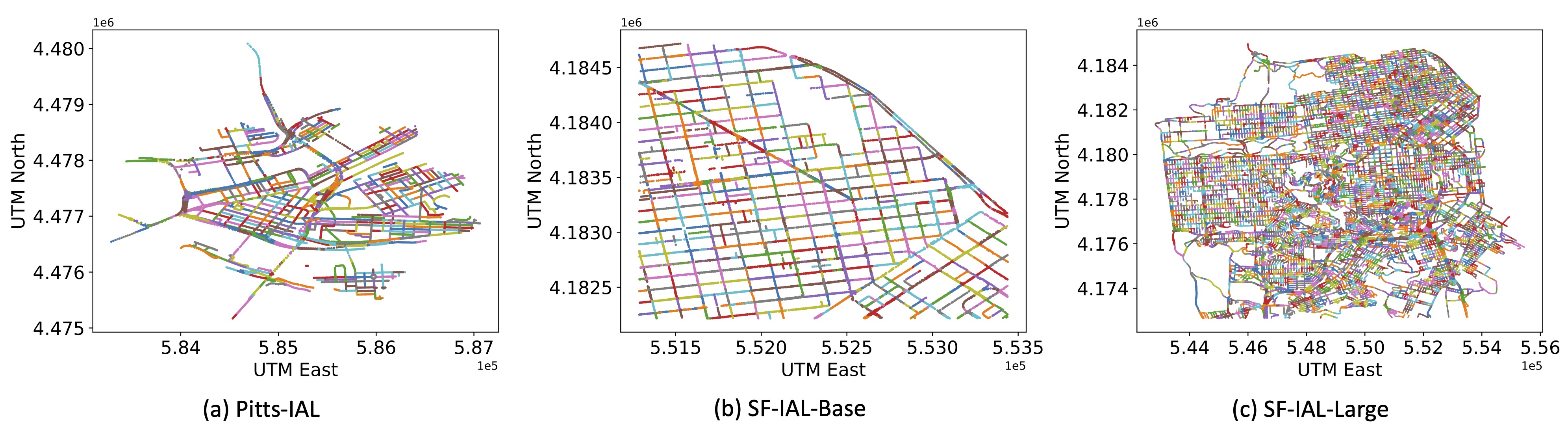
Existing datasets for image geo-localization only contain the GPS coordinates of where the image was taken. Meanwhile, the text in popular image-text datasets like LAION-5B mainly describes the semantic content of the corresponding image instead of the geographical information. To support the study of the IAL problem, we introduce three IAL datasets named Pitts-IAL, SF-IAL-Base, and SF-IAL-Large derived from Pitts-250k and SF-XL, respectively. An example of the address annotation is provided in the above figure, and the visualizations of the proposed dataset is given below.
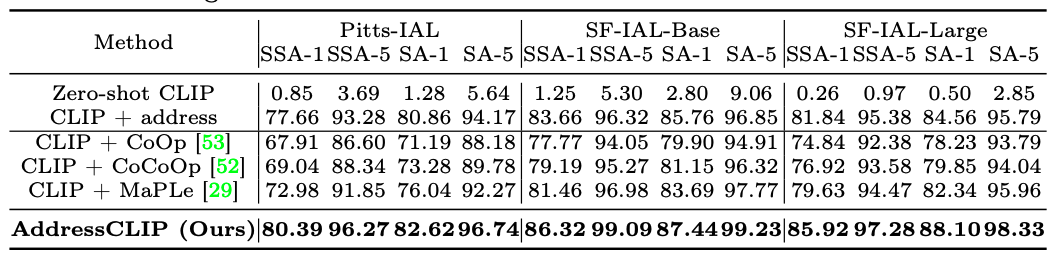
The above table shows the comparison results with the above baselines on the introduced Pitts-IAL, SF-IAL-Base, and SF-IAL-Large datasets. It is clear that our method achieves remarkable performance on the three datasets across various metrics. The zero-shot CLIP model exhibits poor performance due to the lack of explicit address information in the image-text pairs during pre-training. After fine-tuning CLIP with address, the address localization accuracy improves significantly on all three datasets, forming a strong baseline. Benefiting from carefully designed image-text alignment and image-geography matching mechanisms, our AddressCLIP surpasses the representative visual- language prompt learning methods by 7.41%, 4.86%, and 6.29% on Pitts-IAL, SF-IAL-Base, and SF-IAL-Large datasets respectively in terms of SSA-1. This indicates that general prompt learning methods that transfer pre-trained models to various downstream tasks are inferior to those specifically designed, especially when the domain of the downstream task (IAL) differs significantly from that of the pre-trained. It is noteworthy that our method generally performs better on the SF-IAL-Base dataset than on the Pitts-IAL dataset due to more orderly streets and the greater density of street view image collection. Remarkably, our method achieves an address location accuracy of 85.92% even on the more chal- lenging SF-IAL-Large dataset, which covers an area 8× larger than the Pitts-IAL dataset. Additionally, performance on the SA metric is typically higher than the SSA metric, suggesting that using sub-streets as the learning target can further enhance the localization capability for main streets.
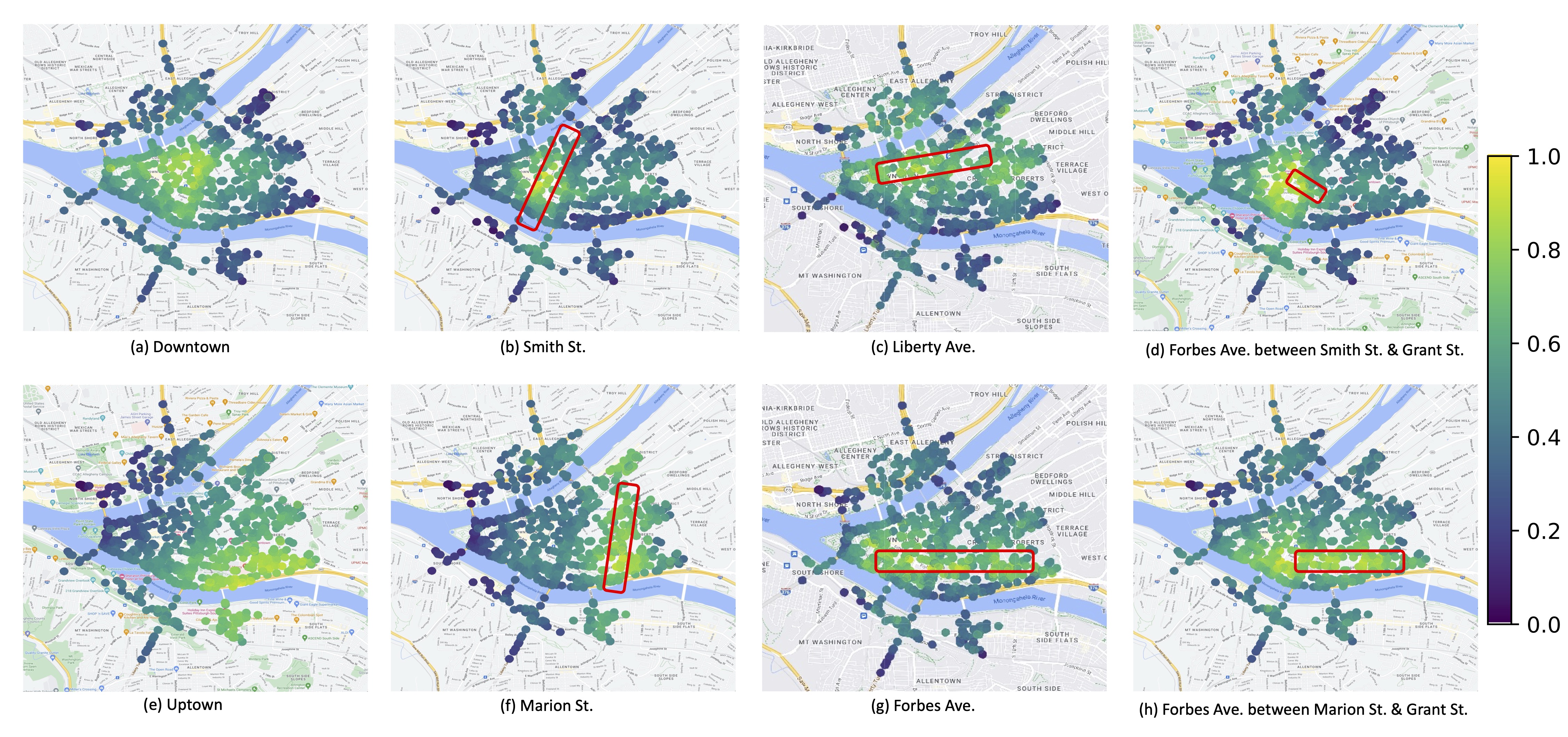
As shown in above figure, address localization with a given textual address query using AddressCLIP in Pittsburgh. The brighter the scatter point, the higher the similarity of the embedding between the image and the query address text. The red box represents the actual geographic range of the query street in the map.
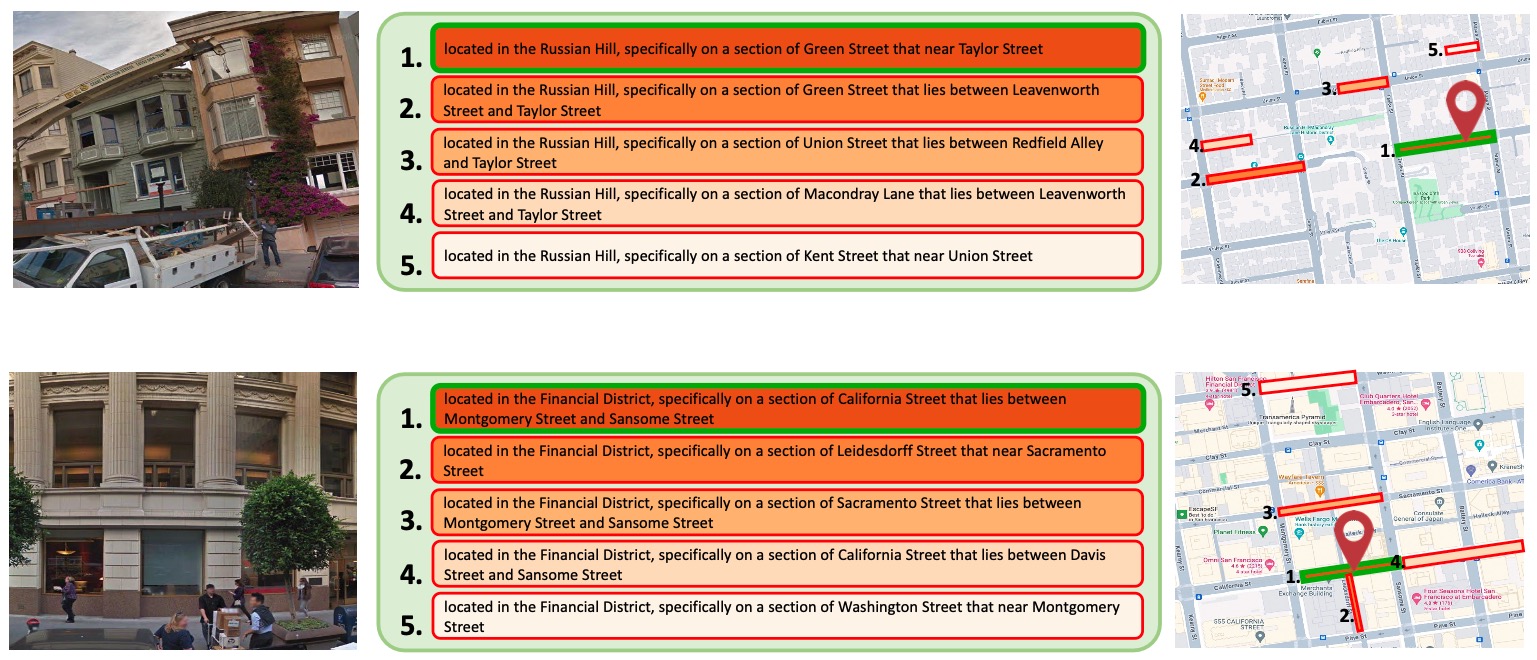
This figure shows the Top-5 textual address predictions generated by the proposed AddressCLIP, based on given image queries, along with their locations on the map. The examples provided come from the Pitts-IAL and SF-IAL-Base datasets. In the majority of cases, the correct prediction is identified within the first ad- dress (Top-1), demonstrating AddressCLIP’s precise address localization capa- bility. Subsequent predicted addresses are also close to the correct location. Ad- ditionally, we showcase some failure examples where the Top-1 prediction is not correct. Even so, the correct address can still be predicted within the Top-5 ad- dresses, and the Top-1 predicted address is typically close to the actual location.
@inproceedings{Xu_2024_ECCV,
title={AddressCLIP: Empowering Vision-Language Models for City-wide Image Address Localization},
author={Xu, Shixiong and Zhang, Chenghao and Fan, Lubin and Meng, Gaofeng and Xiang, Shiming and Ye, Jieping},
booktitle={European Conference on Computer Vision (ECCV)},
year={2024}}